
Generating cluster-wide unique IDs

Lets look at a rather interesting problem that is pretty common in distributed systems where generating unique IDs in a cluster is not as simple as it sounds. Lets begin by defining the problem statement and then build upon the idea.
Problem statement: Generate a cluster wide unique id, assume that this unique id is provided by a service. This service is replicated on a cluster of nodes each one being stateless. During increasing load this service can get called multiple times (10,000 times a second) , increasingly so even at the same time.
Lets explore some ideas of how we can think of this problem.
Idea 1: Keeping a global set of ids
This is sort of the first idea that comes to mind. You can ensure uniqueness by just creating a global set of unique integers. We can use random number generator with a seed to spit out a random number. When your random number generator generates a random id you could go check if it exists and if not just insert it in our global set.Easy peasy.
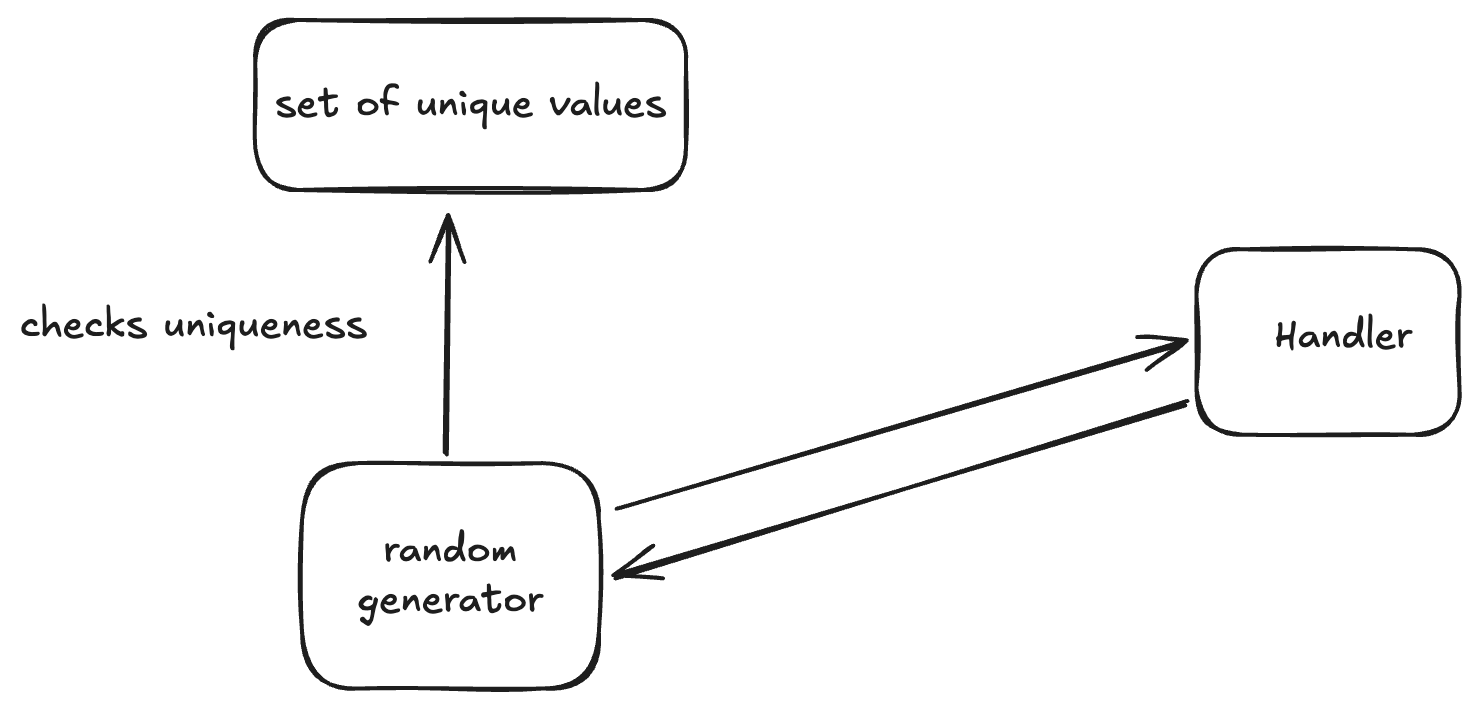
Caveat: The caveat here is that two nodes could be called at the same time, causing our global table to accessed at the exact same time, since one of the nodes would determine that the key that it is looking for does not exist. We could ensure atomicity by locking the data structure which could be an alternate solution i could have explored but for the simplicity of this exercise I did not go down that route. But it could be an interesting discussion.
Approach 2: Using the unix microsecond timestamp
This approach came next to my mind. We could pull out a unix microsecond function from any language, that would allow us to be more globally unique since it would take the current timestamp and then convert it into a unix timestamp in microseconds which is an extremely small unit . Return this timestamp to the caller and voila, we have a unique timestamp. This makes the code cleaner and eliminates the unique set we need to keep. Minor win.. or is it ?

Caveat: in this approach like the last one it could be possible that the function is called simultaneously at the same microsecond (which is thought is unlikely but just assume we have an extremely popular service), therefore it could generate the exact same value, leading to duplicates. At this point its pretty clear we need to have some sort of combination of approaches.
Approach 3: Combination of microsecond timestamp and a process counter.
I needed to do some googling to come up with this one. It was not so obvious to me. This approach involves using a shared atomic counter seq that auto increments and would guarantee uniqueness across processes. Let take an example.
Node 1: Timestamp: 10, Shared counter: 1, Final ID: 101
Node 2: Timestamp: 10, Shared counter: 2 , Final ID: 102
We can do some mathematical operations like OR and bitshifting to get a unique iD but this one is the most simple. Take the two timestamps, convert them to strings and then concatenate the strings to get the unique id. In concurrent processes or processes with multiple threads this comes handy.
Note:
In Go, the statement
c := atomic.AddUint64(&seq, 1)uses thesync/atomicpackage to safely increment a shared 64-bit unsigned integer (seq) and return the new value.

Additional pointers:
We could have used the node id if our service maintains something like that to ensure uniqueness since the node id would be different for each node.
Mathematical operations like OR and bitwise shifting for the last approach are perfectly valid solutions for this problem
I have not explored the idea of atomicity of the database for ID generation, perhaps we would be able to guarantee atomicity and consistency but I did not give it much thought. Would love to hear any ideas if you have any.