
Multi-Node Broadcast Challenge: Brute force
Send a broadcast message to all nodes

Lets talk about deduplication of values and broadcast of messages. In the previous blog it was extremely simple, all we had to do was broadcast a message and then receive it, ensuring our handlers worked fine.
Goal: deliver every unique message to every node.
In a multi node broadcast system we need to ensure that a message is broadcasted over an entire system. The first idea that came to my mind was pretty simple, when we get a value that is broadcasted, we gather the nodes in the topology that are neighbors of that node and then send to all the neighbors in the list. Pretty simple right and your right it is.
Note: When you send a message to a node it sends back a broadcast_ok message back, this is an important piece of information.
I did not check for this message, all i did was fire off and forget, which was a grave mistake on my part.
Steps
a) Receive a broadcast message
b) Iterate through the neighbors
c) Send broadcast message to all neighbors
The diagram below makes it simple to visualize.
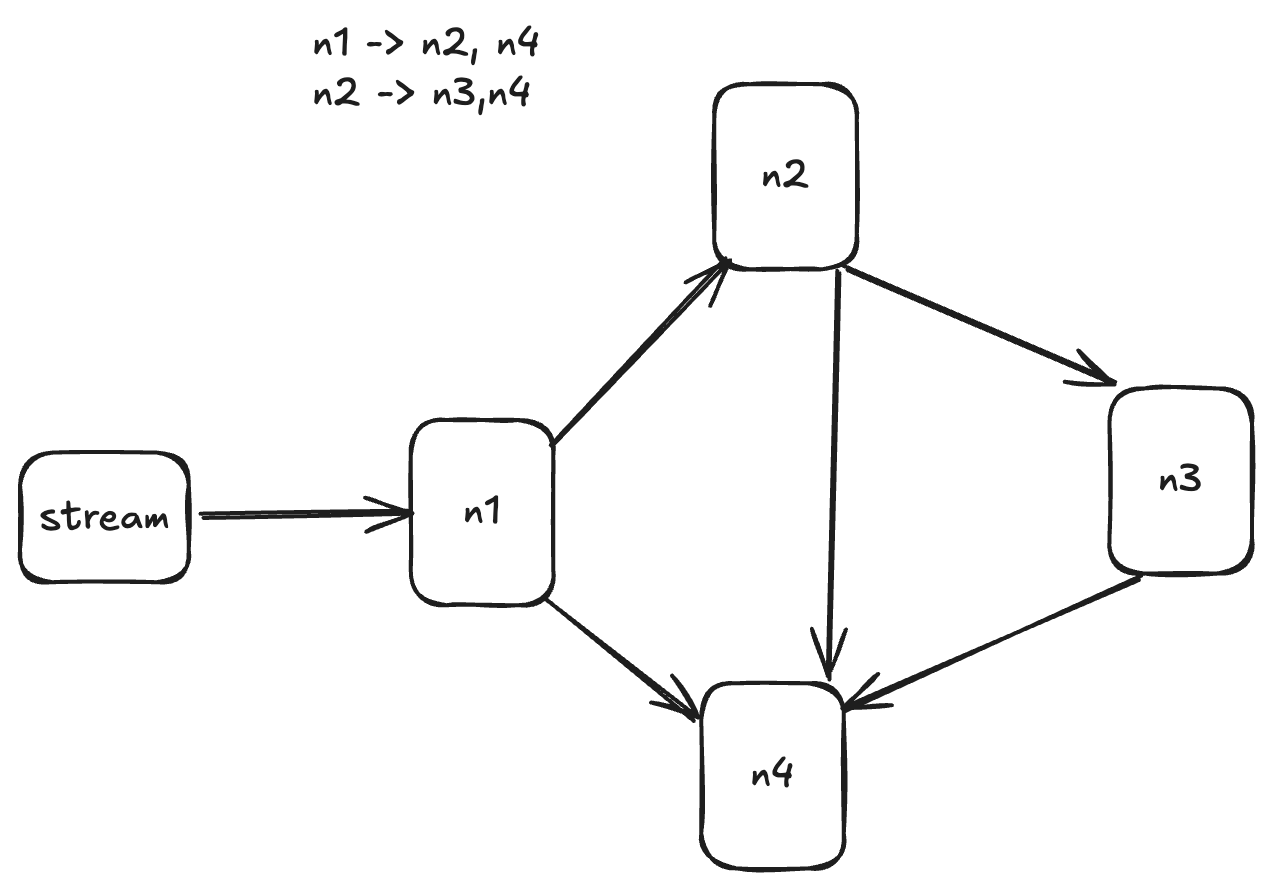
Catch
The way the challenge is designed it is totally possible that due to a network partition that a node does not send the broadcast message and in that case since the way we have designed the system, we do a send and forget, which clearly did not work in our chase. So the next challenge is to figure out a retry mechanism or some sort of a worker that will retry messages that are not getting broadcasted.
Side Notes
Command:
maelstrom test -w broadcast --bin ./your_bin --time-limit 20 --node-count 5 --rate 100Expect: no missing deliveries, no duplicates, stable latency
Example passing line:
:valid? true :lost 0 :duplicated 0 :unexpected 0
Takeaway
Idempotency first (dedup), then reliability (acks+retries), then healing (anti-entropy).