

Lets look at what happens when we write a go routine in golang and how does the scheduler deal with it.
Goroutine scheduler: The scheduler’s job is to distribute ready-to-run goroutines over worker threads.
When you write go f(), the go compiler and runtime arrange to do the following:
It allocates a small descriptor for the goroutine and a small initial stack
Records the entry function f and its arguments in that descriptor
Place this new goroutine onto a run queue so it can be scheduled.
Lets understand what is the schedulers basic model
G = The goroutine which has the function the stack and the metadata
M = The OS thread that actually runs code on a CPU core
P = The processor that allows an OS thread to run code. It owns queues of go routines.
Diagram
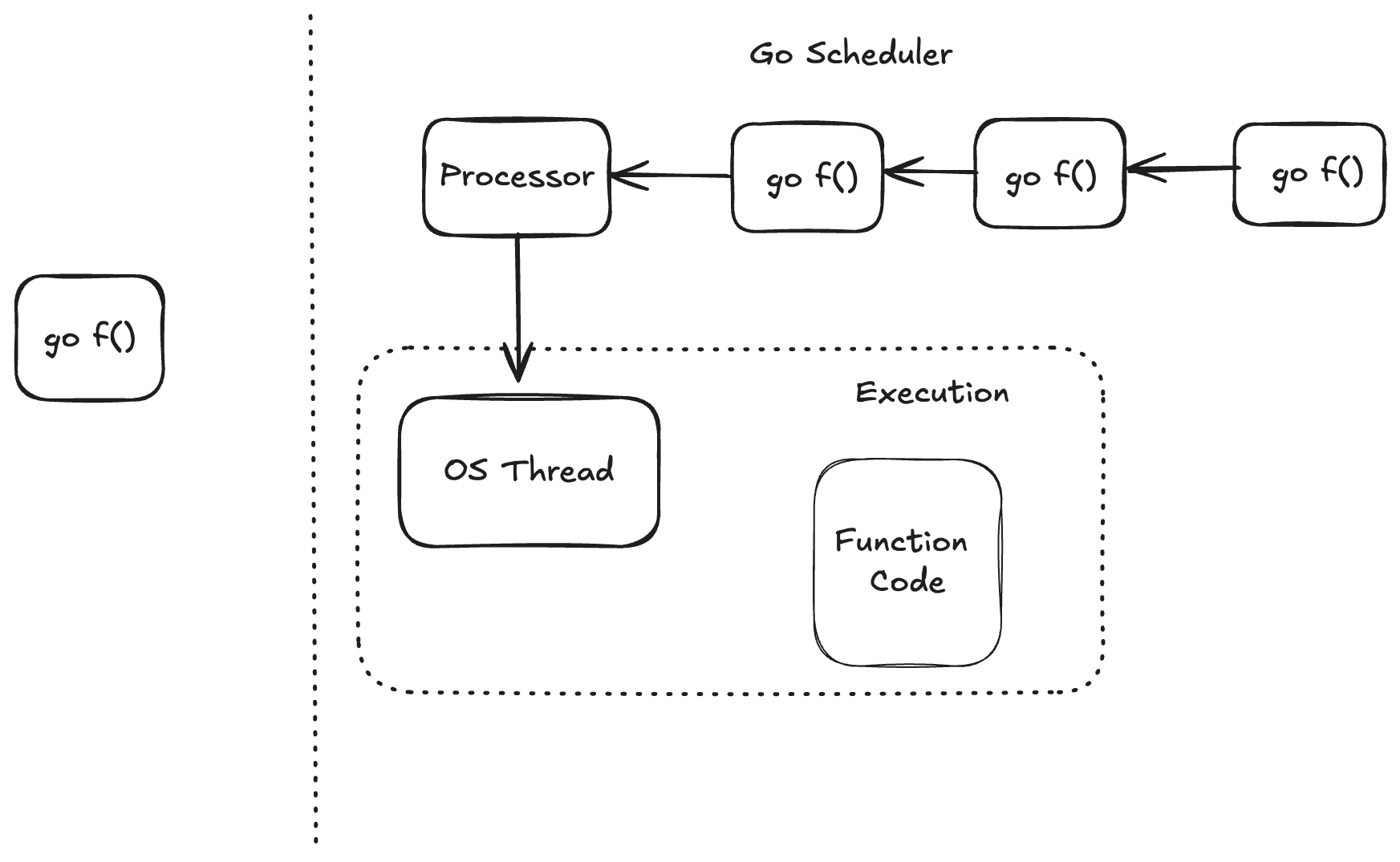
How does your function actually get time ?
go f(x)compiles to a call into the runtime that:allocates a G with a small stack (growable).
records entry
fand its args.pushes G onto the current P’s local run queue (or global if needed),
may wake/start an M if there’s idle work but no running worker.
An M that owns that P runs the scheduler loop:
pop a runnable G from the P’s local queue (or global / steal).
switch to the G’s stack and call
f.preempt/park on syscalls, channel/blocking, GC safepoints etc.
If a goroutine blocks (syscall/channel), the M may park or hand the P to another M so the run queues keep draining.
Historical breadcrumb:
In older Go sources (e.g., Go 1.1 era), you’ll see the same idea in functions like
startm/wakep: when a G becomes runnable, the runtime tries to ensure a P has a running M so work doesn’t idle.If you peek at today’s
runtime/code, search fornewproc,schedule,runq, andstartminproc.gonames are readable even if details changed.